数据库性能优化报告
序号 | 版本号 | 编制/修改日期 | 修改内容 | 修改人 |
1 | V1.0 | 2019-6-11 | 数据库性能优化报告 | 天凯科技-冯工 |
一、 性能现状
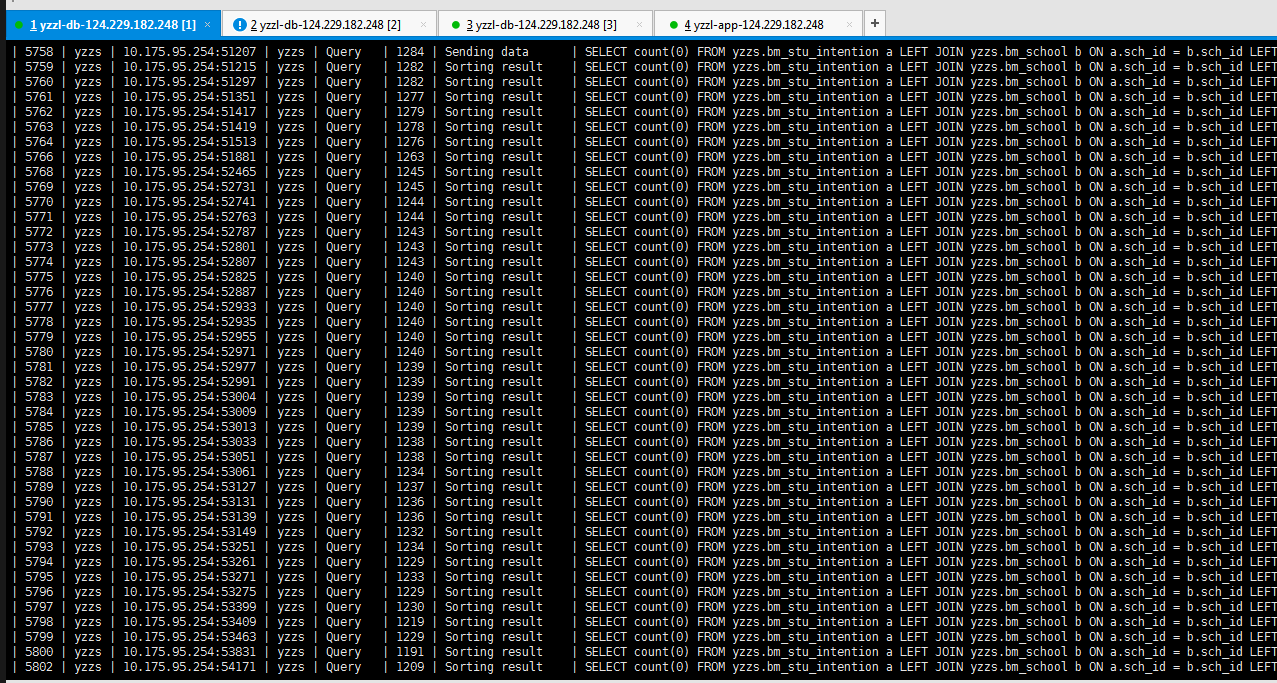
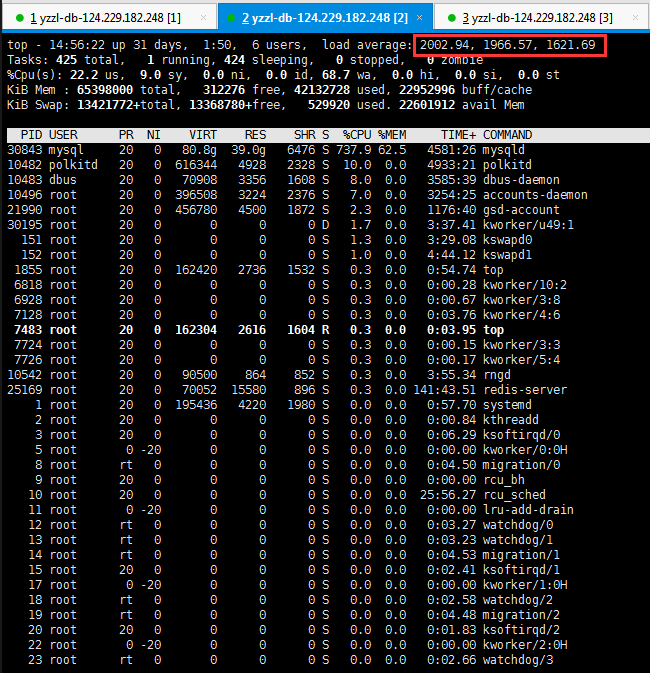
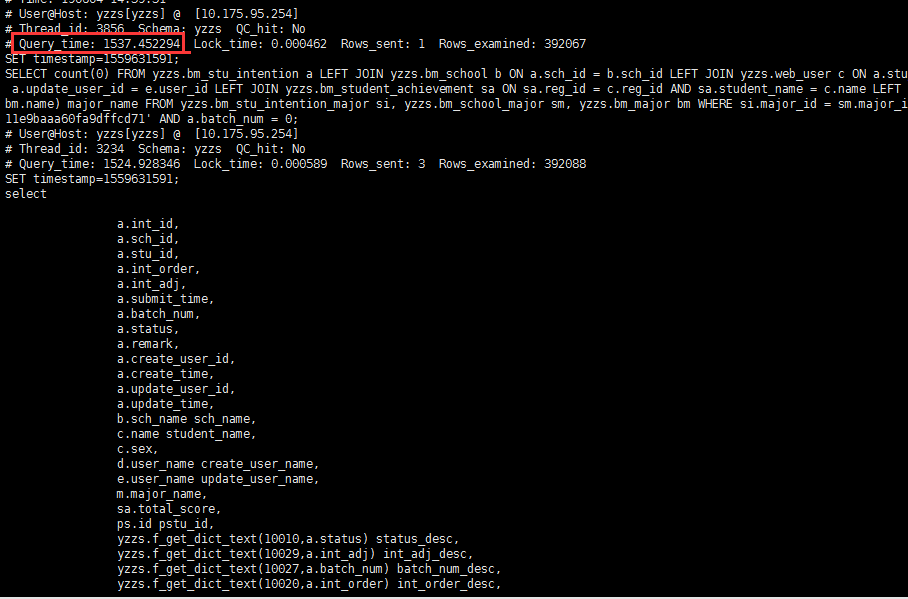
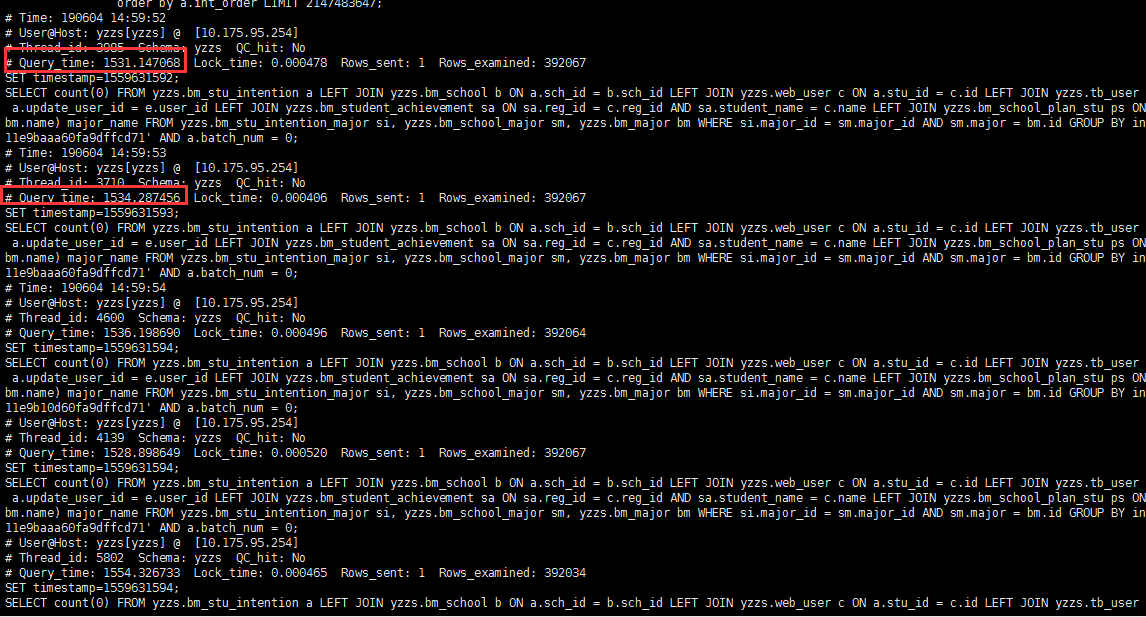
经过一段时间对数据库的性能监控,发现数据库整体负载极高,从LINUX系统的负载来看,平均活动会话高达2000个/秒以上。业务经常出现卡死堵塞状况,此时需要运维人员重启DB才能缓解,但经过一段时间后问题依旧重现。结合下面慢日志报告进一步分析,部分高并发查询SQL请求非常频繁和低效,数据库连接进程队列达到2000个以上,系统出现严重拥堵状况! DML写操作也存在一定的行锁冲突,效率也较慢,经常出现锁表现象;经过后续的SQL分析和客户的反映,该系统运作多年没做任何优化,此类SQL存在很大的优化空间,下面详细介绍这些SQL的优化过程,并在优化前后分别做了负载基线与采样,后续运行了性能对比报告,可直观地反映出这次性能优化的效果。
二、 优化方案
数据库性能问题很大程度上是由于应用引起的,而应用反映在数据库层面就是SQL代码,所以一个数据库的性能90%以上是由于SQL代码的设计和访问路径不当引起的性能问题,下面是对数据库TOP SQL语句的优化记录,目前已对大部分消耗较高的SQL进行了调整,从后续的优化报告来看,已极大减少了IO的消耗,从而提高数据库的性能效率;另外从数据库的配置参数层面出发,也存在一定的优化空间,下面也给出调整优化SQL的具体操作步骤(注意:下面是罗列了一些关键SQL的优化记录,还有部分优化记录没有贴上)。
2.1 优化记录1
SELECTcount(0)
FROM yzzs.bm_stu_intention a
LEFTJOIN yzzs.bm_school b
ON a.sch_id = b.sch_id
LEFTJOIN yzzs.web_user c
ON a.stu_id = c.id
LEFTJOIN yzzs.tb_user d
ON a.create_user_id = d.user_id
LEFTJOIN yzzs.tb_user e
ON a.update_user_id = e.user_id
LEFTJOIN yzzs.bm_student_achievement sa
ON sa.reg_id = c.reg_id
AND sa.student_name = c. NAME
LEFTJOIN yzzs.bm_school_plan_stu ps
ON ps.int_id = a.int_id
LEFTJOIN(SELECT int_id, GROUP_CONCAT(bm. NAME) major_name
FROM yzzs.bm_stu_intention_major si,
yzzs.bm_school_major sm,
yzzs.bm_major bm
WHERE si.major_id = sm.major_id
AND sm.major = bm.id
GROUPBY int_id) m
ON a.int_id = m.int_id
WHERE a.stu_id ='e3a1249082de11e9baaa60fa9dffcd71'
AND a.batch_num =0;
n 优化措施:
索引层面优化:
createindex ix_stu_id_batch_num on yzzs.bm_stu_intention(stu_id, batch_num) online;
n 优化分析:创建上面索引后,数据库COST值有较大的下降,性能提升效果不错,此时CPU已从100%下降到50%左右,负载从2000下载到50左右,但鉴于该SQL中间部分(如下图)是做了一个三表关联group by ,这个是一个独立的处理单元,无法通过索引或改写来达到优化效果。
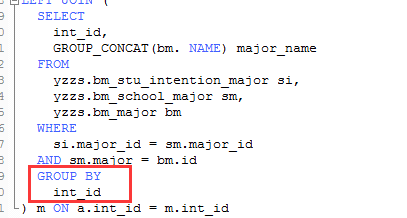
n 进一步优化分析:
针对中间部分的SQL代码,与客户开发人员做针对性沟通,发现该分组代码存在冗余现象,是没有必要的功能,鉴于这种情况,客户可以直接调整应用程序,调整后,效果非常显著,具体数据见下面的:优化效果第三章节。
2.2 优化记录2
SELECTcount(0)
FROM yzzs.bm_stu_intention a
LEFTJOIN yzzs.bm_school b
ON a.sch_id = b.sch_id
LEFTJOIN yzzs.web_user c
ON a.stu_id = c.id
LEFTJOIN yzzs.tb_user d
ON a.create_user_id = d.user_id
LEFTJOIN yzzs.tb_user e
ON a.update_user_id = e.user_id
LEFTJOIN yzzs.bm_student_achievement sa
ON sa.reg_id = c.reg_id
AND sa.student_name = c. NAME
LEFTJOIN yzzs.bm_school_plan_stu ps
ON ps.int_id = a.int_id
LEFTJOIN(SELECT int_id, GROUP_CONCAT(bm. NAME) major_name
FROM yzzs.bm_stu_intention_major si,
yzzs.bm_school_major sm,
yzzs.bm_major bm
WHERE si.major_id = sm.major_id
AND sm.major = bm.id
GROUPBY int_id) m
ON a.int_id = m.int_id
WHERE a.stu_id ='e3a1249082de11e9baaa60fa9dffcd71'
AND a.batch_num =0;
n 优化分析:
该语句其实跟语句1是类似的,优化方向跟方法是一致的,所以当做了上述优化措施后,优化效果会自动覆盖此SQL语句。
2.3 优化记录3
SELECT a.detial_id,
a.plan_id,
a.major_id,
a.plan_num,
a.plan_fee,
a.plan_to,
a.major_for,
a.remark,
a.create_user_id,
a.create_time,
a.update_user_id,
a.update_time,
a.act_num,
IFNULL(a.act_num,0) act_numes,
IFNULL(cnt.taked_cnt,0) taked_cnts,
IFNULL(snum.int_num,0) int_num,
b.sch_id,
d.sch_name,
e. NAME major_name,
e. NAME major_full_name,
c.major,
c.major_no,
c.major_desc,
c.major_duration,
p. NAME NAMES,
e.upid,
yzzs.f_get_dict_text(10018, c.major_duration) major_duration_desc,
yzzs.f_get_dict_text(10033, b. STATUS) status_desc
FROM yzzs.bm_school_plan_detail a
JOIN yzzs.bm_school_plan b
ON a.plan_id = b.plan_id
AND b.del =0
AND b.plan_year =YEAR(now())
JOIN yzzs.bm_school_major c
ON a.major_id = c.major_id
AND c.del =0
JOIN yzzs.bm_school d
ON d.sch_id = b.sch_id
AND c.sch_id = d.sch_id
LEFTJOIN yzzs.bm_major e
ON c.major = e.id
LEFTJOIN yzzs.bm_major p
ON p.id = e.upid
LEFTJOIN(SELECT major_id, sch_id,count(1) taked_cnt
FROM yzzs.bm_school_plan_stu sps
WHERE sps.take_stauts IN(0,1,2)
GROUPBY sps.major_id, sps.sch_id) cnt
ON a.major_id = cnt.major_id
LEFTJOIN(SELECT major_id,count(1) int_num
FROM yzzs.bm_stu_intention_major ima
WHERE ima. STATUS =0
GROUPBY ima.major_id) snum
ON a.major_id = snum.major_id
WHERE b.sch_id ='2152a60b65a411e9b4a8507b9dc07fa5'
ORDERBY p.sorts, c.major_no LIMIT2147483647;
n 索引优化:
create indexix_sch_id onyzzs.bm_school_plan(sch_id);
n 优化分析:创建上面索引后,该语句的COST值有较大的下降,性能提升效果不错,此时CPU已从100%下降到50%左右,负载从2000下载到50左右,但鉴于该SQL中间部分做了group by,情况大致与语句1相似 ,这个是一个独立的处理单元,无法通过索引或改写来达到优化效果。
n 进一步优化分析:
针对中间部分的SQL代码,与客户开发人员做针对性沟通,发现该分组代码存在冗余现象,是没有必要的功能,鉴于这种情况,客户可以直接调整应用程序,调整后,效果非常显著,具体数据见下面的:优化效果第三章节。
2.4 优化记录4
updateyzzs.tb_login_log
SET ….
where user_id = 'bb0b415086c411e980fb60fa9dffcd71',
优化措施:create indexidx_login_log_userid on tb_login_log(user_id);
n 优化分析:改更新语句缺失索引,创建后,rows扫描从23W+下降到17,优化效果明显。
2.5 其他优化
数据实例参数存在优化空间,下面是调整数据库参数达到优化效果:
innodb_thread_concurrency=32
innodb_buffer_pool_size=40G
n 分析:innodb_thread_concurrency表示SQL经过解析后,允许同时有32个线程去innodb引擎取数据,如果超过32个,则需要排队;另外目前DB服务器的物理内存为64G,并且数据库所有表的存储引擎均为innodb,所以将innodb_buffer_pool_size核心内存参数调整到40G,增加其访问效率。
三、 优化效果
在对数据库做性能优化前,我们做了LINUX系统与数据库性能基线报告,也就是能反映数据库在优化前的性能状态,然后在优化后采集同样的性能数据报告,下面就是优化后的报告的内容截图,从这个差别报告来看,我们可以比较直接地反映出这次性能优化的效果。
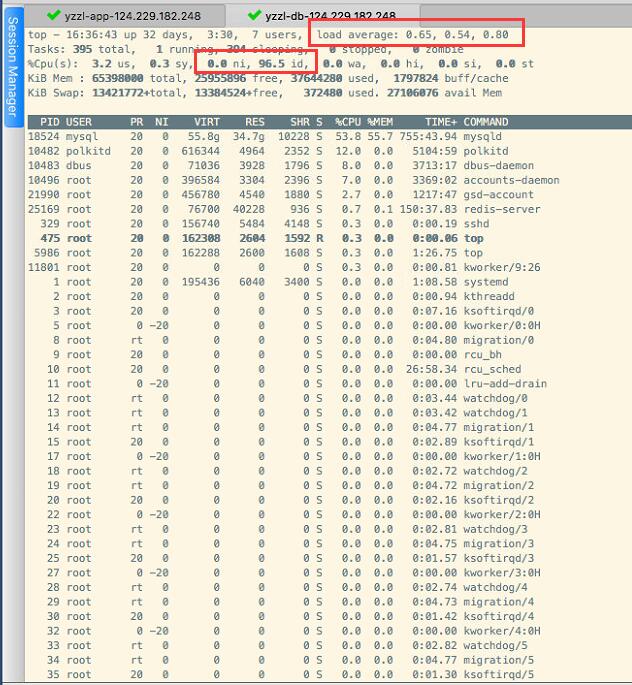
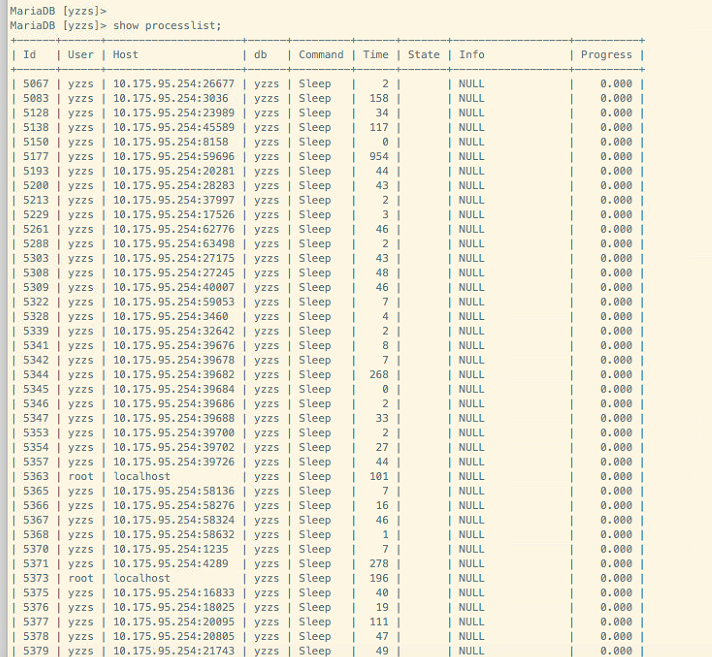
报告分析说明:
从上面的性能数据报告来看,优化效果还是有非常巨大效益的,首先从数据库的负载方面来看,优化后,数据库的负载从2000+下降到1以下(这个数值是表示1秒内有多少队列正处于排队等待状态,很显然,优化前的2000已使系统处于瘫痪状态,优化后,响应速度已畅通无阻),LINUX系统的负载来看,CPU负载从原来的10下降到到0.7左右,从数据库等待事件方面来看,优化前存在严重的read by other session等待,优化后该等待事件已消失,并且DML写操作阻塞已消失,数据库以CPU TIME等待为主,该事件如占比在90%以上,说明性能非常理想,并且优化前出现的业务卡死情况,需要定期重启DB来缓解的问已彻底解决。总的来说,本次优化效果显著,保守估计,数据库整体性能500%的提升目标已超额完成,下面列出优化前后的关键性能指标对比。
性能指标 | 优化前 | 优化后 |
数据库连接队列(活动processlist) | >2000 | <100 |
Linux系统CPU负载 | >2000 | <1 |
Linux系统CPU利用率 | 接近100% | <10% |
数据库锁阻塞数 | 每分钟10次左右 | 没有发生 |
业务运作状况 | 业务操作经常卡死,缓慢等待, 必须重启DB来解决 | 业务操作畅通无阻,无异常状况出现 |
公司地址:广州市南沙区丰泽东路106号
公司官网:www.dbs-service.com
电话/微信:13926108245
QQ客服:282321952
发表评论 取消回复